
Trong vài thập kỷ qua, ngành Kỹ thuật phần mềm chỉ xoay quanh một mục tiêu duy nhất: loại bỏ sự mơ hồ. Điều đó có nghĩa là xác định các giao diện (interface) nghiêm ngặt, thực thi tính an toàn về kiểu dữ liệu (type safety) và đảm bảo rằng: Đầu vào A + Mã nguồn B = Đầu ra C.
Kỹ thuật phần mềm truyền thống mang tính Xác định (Deterministic). Chúng ta đóng vai trò là những Người điều phối giao thông; chúng ta sở hữu những con đường, đèn tín hiệu và luật lệ. Chúng ta quyết định chính xác dữ liệu đi đâu và khi nào. Nhưng Kỹ thuật Agent lại mang tính Xác suất (Probabilistic). Chúng ta là những Người điều phái (Dispatchers). Chúng ta đưa ra chỉ dẫn cho một tài xế (LLM) – người có thể đi đường tắt, bị lạc, hoặc quyết định leo lề vì cảm thấy "thế thì nhanh hơn".
Có một nghịch lý là các kỹ sư ít kinh nghiệm (junior) thường triển khai các Agent hoạt động tốt nhanh hơn các kỹ sư dày dạn (senior). Tại sao? Kỹ sư càng có nhiều kinh nghiệm, họ càng ít tin tưởng vào khả năng suy luận và tuân thủ chỉ dẫn của Agent. Chúng ta cố gắng chống lại mô hình và tìm cách "lập trình để loại bỏ" bản chất xác suất đó.
Dưới đây là 5 ví dụ cho thấy thói quen kỹ thuật truyền thống xung đột với thực tế mới của Kỹ thuật Agent.
1. Văn bản là Trạng thái mới (Text is the New State)
Trong kỹ thuật truyền thống, chúng ta mô phỏng thế giới bằng các cấu trúc dữ liệu. Chúng ta định nghĩa schema, interface và các kiểu dữ liệu nghiêm ngặt. Điều này tạo cảm giác an toàn vì nó có thể dự đoán được. Theo bản năng, chúng ta cố gắng ép các Agent vào chiếc hộp này.
- Sai lầm (The Trap): Ý định, sở thích hoặc cấu hình trong thế giới thực hiếm khi mang tính nhị phân hoặc có cấu trúc hoàn hảo. Đầu vào của người dùng là liên tục (ngôn ngữ tự nhiên) chứ không phải rời rạc (các trường dữ liệu có cấu trúc).
Văn bản là Trạng thái mới. Chúng ta phải từ bỏ sự thoải mái của các biến boolean (đúng/sai) để chuyển sang ý nghĩa ngữ nghĩa (semantic meaning).
Hãy tưởng tượng trường hợp phê duyệt kế hoạch nghiên cứu chuyên sâu, nơi người dùng nói: "Kế hoạch này trông ổn đấy, nhưng hãy tập trung vào thị trường Mỹ nhé." Một hệ thống xác định sẽ ép điều này vào biến
is_approved: true/false và chúng ta đã "cắt bỏ" mất ngữ cảnh quan trọng.Kỹ thuật phần mềm truyền thống:
{
"plan_id": "123",
"status": "APPROVED" // Sắc thái bị mất ở đây
}
Kỹ thuật Agent:
{
"plan_id": "123",
"text": "Kế hoạch này trông ổn đấy, nhưng hãy tập trung vào thị trường Mỹ nhé."
}
Bằng cách giữ nguyên văn bản, Agent ở bước sau có thể đọc được phản hồi ("Phê duyệt, nhưng tập trung vào Mỹ") và điều chỉnh hành vi của nó một cách linh hoạt.
Một ví dụ khác là sở thích người dùng. Hệ thống truyền thống có thể lưu trữ
is_celsius: true. Hệ thống Agent sẽ lưu trữ: "Tôi thích độ C cho thời tiết, nhưng hãy dùng độ F khi nấu ăn". Agent có thể thay đổi ngữ cảnh linh hoạt dựa trên nhiệm vụ.2. Trao quyền kiểm soát
Trong kiến trúc microservices, ý định của người dùng khớp với một lộ trình (route) cụ thể (ví dụ:
POST /subscription/cancel). Trong Agent, chúng ta chỉ có một điểm đầu vào ngôn ngữ tự nhiên duy nhất với một "Bộ não" (LLM) – nơi quyết định luồng điều khiển dựa trên các công cụ sẵn có, đầu vào và chỉ dẫn.- Sai lầm: Chúng ta cố gắng lập trình cứng (hard-code) luồng công việc vào Agent, nhưng các tương tác thực tế không đi theo đường thẳng. Chúng lặp lại, quay lui và xoay trục. Người dùng có thể muốn hủy dịch vụ, nhưng cuối cùng lại đồng ý gia hạn.
- Người dùng: "Tôi muốn hủy gói thuê bao." (Ý định: Rời bỏ)
- Agent: "Tôi có thể giảm giá 50% để bạn ở lại."
- Người dùng: "À, được đấy, vậy thì ổn." (Ý định: Ở lại)
Hãy tin tưởng Agent trong việc điều hướng luồng hội thoại. Nếu chúng ta cố gắng lập trình cứng mọi trường hợp ngoại lệ (edge case), chúng ta không thực sự xây dựng một AI Agent. Chúng ta phải tin vào khả năng hiểu ý định hiện tại của Agent dựa trên toàn bộ ngữ cảnh.
3. Lỗi cũng chỉ là một dạng đầu vào
Trong phần mềm truyền thống, nếu một lệnh gọi API thất bại hoặc thiếu một biến, chúng ta sẽ ném ra một ngoại lệ (exception). Chúng ta muốn chương trình dừng lại ngay lập tức để có thể sửa lỗi.
- Sai lầm: Một tác vụ của Agent có thể mất 5 phút và tốn 0.50 USD. Nếu bước 4 trên 5 bị lỗi do thiếu hoặc sai đầu vào, việc làm sập toàn bộ quá trình thực thi là điều không thể chấp nhận được.
- Lỗi cũng chỉ là một loại đầu vào khác. Thay vì làm sập chương trình, chúng ta bắt lỗi đó, đưa nó ngược lại cho Agent và cố gắng phục hồi.
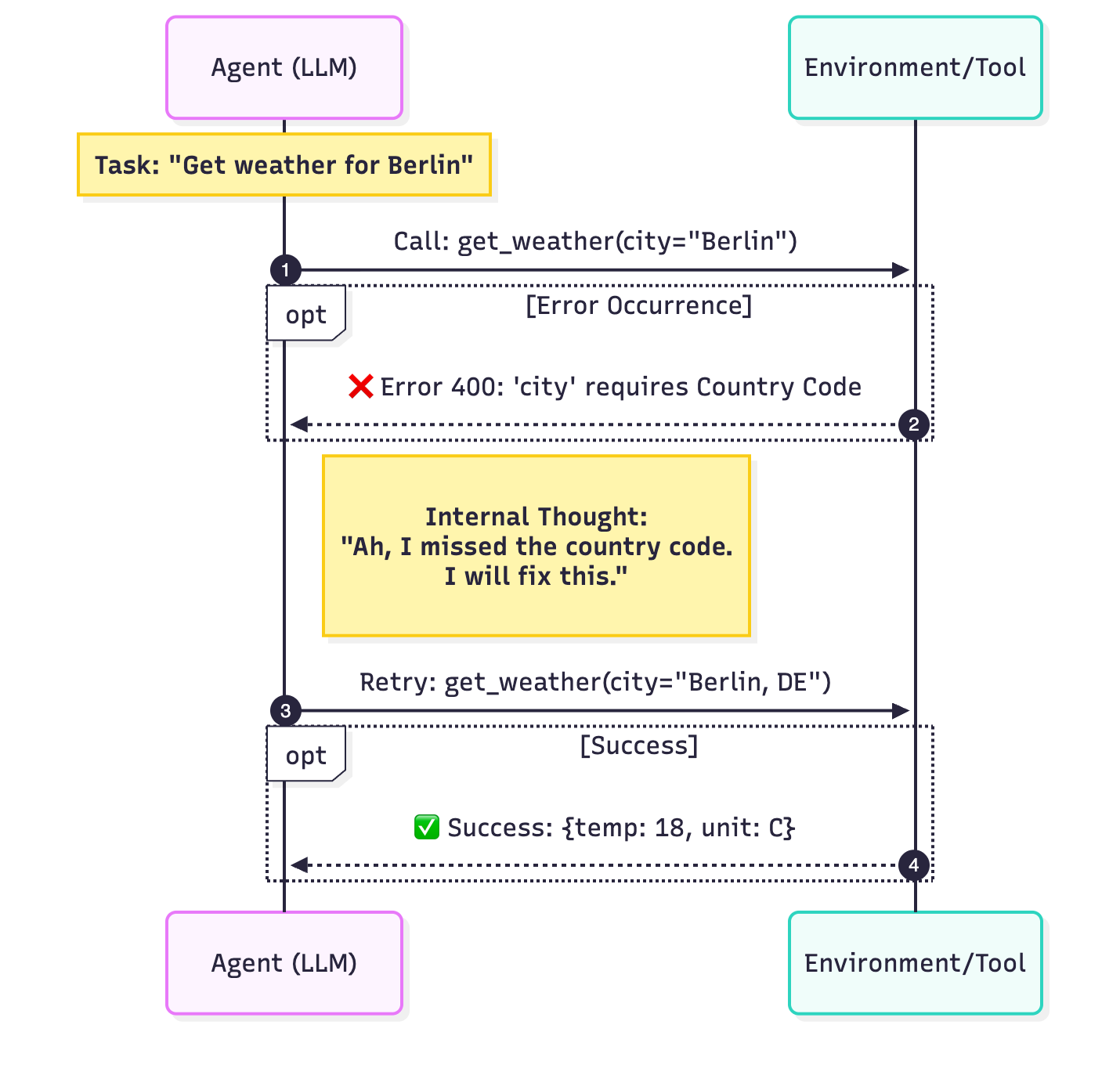
4. Từ Unit Test chuyển sang Evals (Đánh giá)
Lập trình hướng kiểm thử (TDD) giúp chúng ta viết mã nguồn ổn định hơn, nhưng chúng ta không thể "unit test" một Agent. Các kỹ sư có thể lãng phí hàng tuần để tìm kiếm sự chính xác tuyệt đối (binary correctness) trong một hệ thống mang tính xác suất. Thay vào vào đó, chúng ta phải đánh giá hành vi.
- Sai lầm (The Trap): Chúng ta không thể viết các khẳng định đúng/sai (assertions) cho các tác vụ sáng tạo hoặc suy luận. Câu lệnh "Hãy tóm tắt email này" có vô số kết quả đầu ra hợp lệ. Nếu chúng ta cố gắng "Mock" (giả lập) LLM, chúng ta không phải đang kiểm thử Agent, mà đang kiểm thử khả năng nối chuỗi của chính mình.
Evals quan trọng hơn Tests. Chúng ta không thể unit test khả năng suy luận. Chúng ta phải xác thực Độ tin cậy và Chất lượng, đồng thời truy vết các bước kiểm tra trung gian:
- Độ tin cậy (Pass^k): Chúng ta không hỏi "Nó có chạy không?". Chúng ta hỏi "Nó chạy đúng bao nhiêu lần?".
- Chất lượng (LLM làm giám khảo): "Câu trả lời có hữu ích không? Giọng điệu có chuẩn không? Bản tóm tắt có chính xác không?".
- Truy vết (Tracing): Đừng chỉ kiểm tra câu trả lời cuối cùng. Hãy kiểm tra các bước trung gian. Agent có tìm kiếm trong cơ sở tri thức trước khi trả lời không?
Nếu Agent thành công 45/50 lần với điểm chất lượng 4.5/5, nó đã có thể sẵn sàng để triển khai thực tế (production-ready). Chúng ta đang quản trị rủi ro, chứ không phải loại bỏ hoàn toàn sự biến thiên.
5. Agent tiến hóa, API thì không
Trước đây, chúng ta thiết kế API cho các lập trình viên con người, dựa vào ngữ cảnh ngầm hiểu và các giao diện "sạch sẽ". Con người có thể suy luận ngữ cảnh, nhưng Agent thì không. Agent là những kẻ "nghĩa đen". Nếu định dạng ID bị mơ hồ, Agent sẽ tự "ảo giác" ra một cái.
- Sai lầm: Chúng ta thường xây dựng các API "Cấp độ Người dùng" — những endpoint dựa trên ngữ cảnh ngầm định. Ví dụ, một biến tên là
idrõ ràng làuser_unique_identifier(UUID) đối với chúng ta, và có thể dùng trong hàmget_user(id). Một Agent có thể không có ngữ cảnh này và có thể thử đưa email hoặc tên vào biếnidđó.
Agent yêu cầu cách đặt kiểu dữ liệu ngữ nghĩa cực kỳ chi tiết (ví dụ:
user_email_address thay vì email) và các docstring mô tả tỉ mỉ đóng vai trò là "ngữ cảnh".
- Tồi:
delete_item(id)(ID là số nguyên hay UUID? Chuyện gì xảy ra nếu không tìm thấy?) - Tốt:
delete_item_by_uuid(uuid: str)kèm theo mô tả: "Xóa một mục. Nếu không tìm thấy, trả về một chuỗi thông báo lỗi chi tiết."
Hơn nữa, Agent cho phép sự thích nghi ngay lập tức (Just-in-Time). API thông thường là một lời hứa với lập trình viên; chúng ta viết mã dựa trên các API đó rồi rời đi. Nếu chúng ta đổi API từ
get_user_by_id(id) sang get_user_by_email(email), chúng ta phá vỡ lời hứa đó và mọi thứ sẽ sập ngay lập tức. Tuy nhiên, một Agent có thể đọc định nghĩa công cụ mới và tự điều chỉnh theo nó.
Kết luận: Tin tưởng nhưng cần Xác thực
Quá trình chuyển đổi từ các hệ thống xác định sang các Agent xác suất là một trải nghiệm không mấy dễ chịu. Nó đòi hỏi chúng ta phải đánh đổi sự chắc chắn để lấy sự linh hoạt về mặt ngữ nghĩa. Chúng ta không còn sở hữu và biết rõ lộ trình thực thi chính xác của mã nguồn nữa. Thực tế, chúng ta đang bàn giao luồng điều khiển cho một mô hình không xác định và lưu trữ trạng thái ứng dụng bằng ngôn ngữ tự nhiên.
Điều này tạo cảm giác "sai sai" đối với một tư duy được đào tạo dựa trên các giao diện nghiêm ngặt. Nhưng việc cố gắng ép Agent vào một chiếc hộp "xác định" sẽ làm mất đi mục đích của việc sử dụng AI. Bạn không thể dùng code để loại bỏ xác suất. Bạn phải quản lý nó thông qua Evals và Tự sửa lỗi (Self-correction).
Tuy nhiên, "tin tưởng" Agent không có nghĩa là để nó chạy rông. Chúng ta phải tìm điểm cân bằng. Agent sẽ thất bại theo nhiều cách không ngờ tới, nhưng xu thế là rất rõ ràng. Chúng ta phải ngừng cố gắng lập trình để xóa bỏ sự mơ hồ, mà hãy bắt đầu xây dựng các hệ thống đủ kiên cường để xử lý sự mơ hồ đó.
Điều này cũng có nghĩa là bạn cần biết khi nào nên sử dụng các quy trình cố định (Workflows) thay vì Agent tự do. Tôi sẽ đi sâu vào cách kiến trúc sự khác biệt này trong bài viết về Agentic Patterns.
Nguồn bài viết từ Tác giả Phil Schmid


