
Danh mục:
Sharding (phân mảnh cơ sở dữ liệu) là một kỹ thuật mở rộng quy mô (scaling) mạnh mẽ nhưng cũng đi kèm với độ phức tạp cao. Trước khi quyết định áp dụng Sharding, chúng ta cần xem xét kỹ lưỡng các phương án khác và hiểu rõ về kiến trúc này.
Lời mở đầu
Những điều cần cân nhắc trước khi áp dụng Sharding
Trước khi vội vàng áp dụng Sharding, hãy xem xét các phương án tối ưu hóa hạ tầng khác:
1. Cấu hình MMM (Multi-Master Replication)- Sử dụng cấu trúc Master-Slave (hoặc Master-Master) để phân tách lưu lượng đọc (Read) và ghi (Write).
- Hầu hết các tải (load) thường đến từ việc đọc dữ liệu, nên việc mở rộng Read Replica thường giải quyết được phần lớn vấn đề hiệu năng.2. Phân vùng bảng (Table Partitioning)
- Chia nhỏ một bảng lớn thành các phân vùng (partition) dựa trên thời gian hoặc phạm vi dữ liệu.
- Giúp giảm kích thước index và tăng tốc độ truy vấn trên các tập dữ liệu con.
Cốt lõi của cấu trúc Sharding
Nếu các phương án trên không đủ và bạn bắt buộc phải Sharding, hãy chú ý 3 yếu tố chính:
1. Chọn Shard Key (Khóa phân mảnh)- Đây là yếu tố quan trọng nhất. Shard Key quyết định dữ liệu sẽ nằm ở node nào.
- Cần chọn key sao cho dữ liệu được phân bố đều (tránh hot-spot) và các truy vấn thường xuyên nhất có thể định tuyến trực tiếp đến một shard cụ thể.2. Cách xác định Shard (Shard Decision)
- Algorithmic (Ví dụ: Modulo): id % số_lượng_shard. Đơn giản, phân bố đều, nhưng khó mở rộng số lượng shard sau này (cần re-sharding).
- Dynamic (Directory-based): Lưu bảng ánh xạ (lookup table) xem ID nào nằm ở shard nào. Linh hoạt, dễ mở rộng, nhưng bảng ánh xạ có thể trở thành điểm nghẽn (SPOF).3. Phương thức định tuyến (Routing Implementation)
- Client-side: Ứng dụng tự biết phải kết nối đến DB nào.
- Proxy-side: Ứng dụng kết nối qua một Proxy (như ProxySQL, ShardingSphere), Proxy sẽ lo việc định tuyến.
Khi nào thì cần Sharding?
Tiêu chí định lượng (Tham khảo)Không có con số tuyệt đối, nhưng thường được cân nhắc khi:
- Dữ liệu vượt quá dung lượng lưu trữ của một node đơn lẻ.
- Lượng ghi (Write throughput) vượt quá khả năng xử lý của Master node.
- Chỉ số IOPS hoặc kết nối mạng bị bão hòa.Ví dụ cấu hình và mã nguồn (Kotlin/Spring)
📌 Ví dụ cấu hình Sharding (2 Shards) Giả sử chúng ta có 2 DB vật lý đóng vai trò là Shard 0 và Shard 1.
Ví dụ định tuyến Sharding dựa trên Kotlin + Coroutine
Trong môi trường Coroutine, chúng ta có thể lưu thông tin Shard vào CoroutineContext để định tuyến query.
// (Mã giả định tuyến) suspend fun <T> withShard(shardKey: Long, block: suspend () -> T): T { val shardIndex = shardKey % 2 // Ví dụ dùng Modulo return withContext(ShardContext(shardIndex)) { block() } }
Spring + AbstractRoutingDataSource (Cách tiếp cận JDBC)
Spring cung cấp
AbstractRoutingDataSource để thay đổi DataSource động dựa trên key (thường lưu trong ThreadLocal).Transaction trong môi trường Sharding
Đây là phần phức tạp nhất khi làm việc với Sharding.
🔹 Transaction cục bộ (Local Transaction)
Nếu logic nghiệp vụ chỉ tác động đến dữ liệu trên một shard duy nhất, ta có thể dùng transaction DB bình thường.
// Ví dụ: Chỉ cập nhật dữ liệu user trên 1 shard
transactionalOperator.executeAndAwait { tx ->
// Logic update user...
// Update count...
// Tất cả đều nằm trên cùng 1 shard dựa trên userId
}
🔹 Xử lý trên nhiều Shard: Mẫu Transaction bồi hoàn (Compensating Transaction)
Khi cần cập nhật dữ liệu nằm trên 2 shard khác nhau (ví dụ: chuyển tiền từ User A ở Shard 1 sang User B ở Shard 2).
suspend fun transferBalance(senderId: Long, receiverId: Long, amount: Long): Boolean { // 1. Trừ tiền người gửi (Shard A) // 2. Cộng tiền người nhận (Shard B) // Nếu bước 2 lỗi -> Phải hoàn lại tiền cho người gửi (Bước bù trừ) }
Khi cần distributed transaction, phương pháp xử lý bồi hoàn (compensation) theo kiểu Try-Fail-Reverse (như Saga Pattern) thường được ưu tiên hơn là dùng XA (2PC) vì hiệu năng.
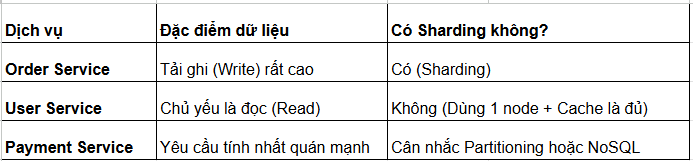
Mối quan hệ giữa MSA và Sharding
Nguyên tắc cốt lõi của MSA (Microservices Architecture) là tách biệt trách nhiệm theo dịch vụ (Bounded Context).
Do đó, thay vì chia nhỏ một DB khổng lồ (Sharding toàn bộ), nguyên tắc là: Mỗi Service sở hữu DB riêng, và việc có áp dụng Sharding hay không là quyết định độc lập của từng Service.
Ví dụ:
Chiến lược Vertical Slicing + Kết nối DB
Khi chia nhỏ dịch vụ theo chiều dọc (Vertical Slicing - theo domain), chúng ta có thể linh hoạt chọn client DB cho từng slice:
-
base-db-client→ Dành cho các domain dùng Single DB. -
sharded-db-client→ Dành cho domain cần Sharding (có logic định tuyến). - Sử dụng chung interface
UserRepositoryvà dùng Dependency Injection (DI) để phân chia.
Cách này giúp giữ cho các service không cần Sharding có cấu trúc đơn giản, chỉ phức tạp hóa những nơi thực sự cần thiết.
Vượt ra khỏi MSA: Cấu trúc Nano Service + BFF
Khi hệ thống MSA trở nên quá lớn:
- Số lượng service tăng -> Vận hành phức tạp.
- Logic tổng hợp dữ liệu bị phân tán -> API cho UI bị chậm.
- Giải pháp có thể là Nano Service + BFF (Backend for Frontend).
Cấu trúc:
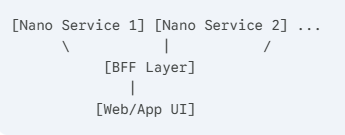
- Nano Service: Chỉ chịu trách nhiệm nguyên tử (atomic), ví dụ: user-profile, user-preference.
- BFF: Chịu trách nhiệm gọi và tổng hợp dữ liệu từ các nano service để trả về định dạng tối ưu cho Client.
- Việc Sharding hay không được ẩn bên dưới Nano Service, BFF không cần quan tâm.
Tổng kết
- Sharding không phải là tính năng "phải có", mà là lựa chọn cuối cùng.
- Hãy thử Cấu hình MMM + Partitioning + Tuning trước.
- Khi áp dụng Sharding, cần thiết kế kỹ về: Shard Key, Chiến lược định tuyến, Transaction, và Tự động hóa vận hành.
- Trong MSA, quyết định Sharding nên nằm ở phạm vi từng Service riêng biệt.
- Sử dụng cấu trúc Vertical Slice để tách biệt độ phức tạp.
- Đẩy việc tổ hợp dữ liệu phức tạp lên BFF hoặc Client.
Nguồn bài viết ryukato.github.io


