
Danh mục:
Tổng hợp về Vận hành Redis Cluster và Chiến lược Client
Tài liệu này tổng hợp các nội dung cốt lõi về sự thay đổi Topology trong môi trường Redis Cluster, cơ chế hoạt động của Client và các chiến lược Read (Đọc). Nội dung được cấu trúc để có thể áp dụng ngay vào thực tế hoặc trả lời phỏng vấn.
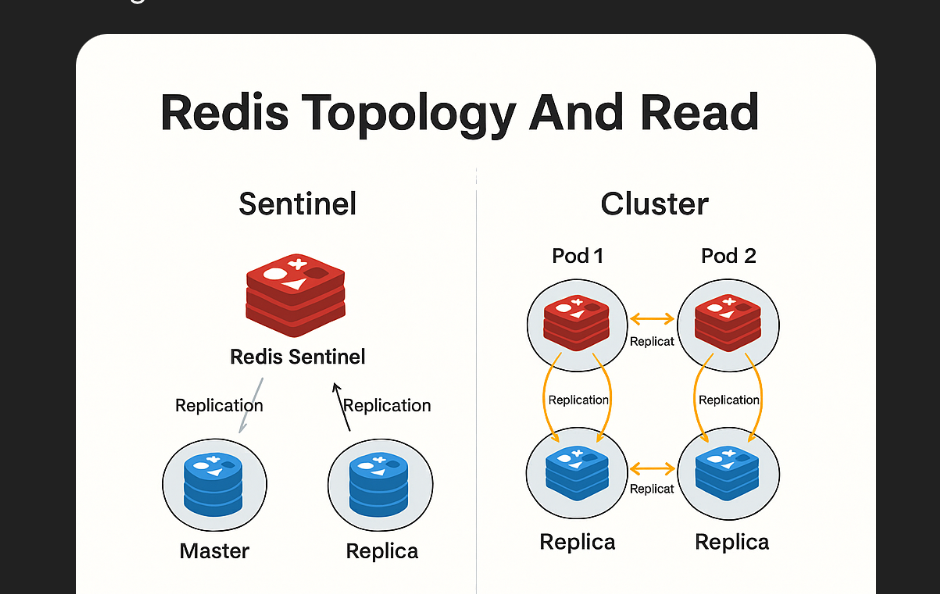
1. Tổng quan về Redis Topology
- Standalone: Vận hành một instance đơn lẻ.
- Master-Slave: Hỗ trợ Read Scale-out thông qua các Slave chỉ đọc.
- Sentinel: Hỗ trợ tự động Failover khi Master gặp sự cố.
- Cluster: Xử lý phân tán dựa trên Sharding + Hỗ trợ tự động Failover.
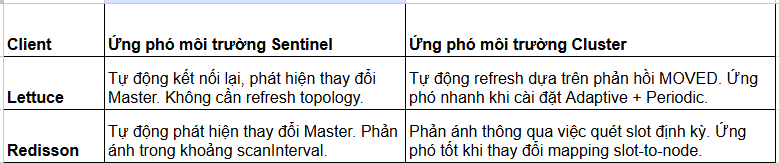
2. Chiến lược ứng phó với thay đổi Topology theo từng Client
Lettuce
- Adaptive Refresh: enableAllAdaptiveRefreshTriggers() (Làm mới khi có tác động).
- Refresh định kỳ: enablePeriodicRefresh(Duration.ofSeconds(10)).
- Có khả năng ứng phó nhanh chóng với các thay đổi Topology.
Ví dụ thiết lập Lettuce (Kotlin/Java)
val topologyRefreshOptions = ClusterTopologyRefreshOptions.builder() .enableAllAdaptiveRefreshTriggers() // Kích hoạt tất cả các trigger thích ứng .enablePeriodicRefresh(Duration.ofSeconds(10)) // Làm mới định kỳ mỗi 10 giây .build() val clusterClientOptions = ClusterClientOptions.builder() .topologyRefreshOptions(topologyRefreshOptions) .build() val redisClusterClient = RedisClusterClient.create(redisURIs) redisClusterClient.setOptions(clusterClientOptions)
Redisson
- scanInterval: Chu kỳ quét topology (Khuyến nghị: 5~10 giây).
- Có khả năng tự động phục hồi sự cố / cập nhật thay đổi slot.
Ví dụ thiết lập Redisson (Dựa trên YAML)
clusterServersConfig: scanInterval: 5000 # Chu kỳ quét 5 giây failedSlaveReconnectionInterval: 3000 retryAttempts: 3 retryInterval: 1500
Tổng kết ứng phó thay đổi Topology (Failover)
3. Điều kiện phát sinh và xử lý phản hồi MOVED
Khi Client tính toán chính xác slot cho một key, nhưng mapping slot-to-node của cụm cluster đã thay đổi: Nếu Client không cập nhật được thay đổi này, lỗi
MOVED sẽ phát sinh: MOVED 12345 192.168.0.10:6379→ Giải pháp: Client thực hiện refresh topology và thử lại yêu cầu.
4. Redis Rebalancing (Tái phân bổ slot)
- Redis không tự động thực hiện rebalancing.
- Chỉ có thể thực hiện thông qua lệnh thủ công:
redis-cli --cluster reshardhoặcrebalance. - Lỗi
MOVEDthường chỉ có khả năng xảy ra khi người vận hành chủ động thực hiện các lệnh này.
5. Chiến lược Read (Đọc) - ReadFrom
Cả Lettuce và Redisson đều hỗ trợ các chiến lược sau:
MASTER: Luôn đọc từ Master (Đảm bảo dữ liệu mới nhất).
REPLICA: Luôn đọc từ Slave (Ưu tiên hiệu năng, không đảm bảo mới nhất).
REPLICA_PREFERRED: Ưu tiên Slave, nếu không có thì quay về Master (Fallback).
NEAREST: Chọn node gần nhất dựa trên độ trễ (latency).
Khuyến nghị thực tế
- MASTER: Dành cho dữ liệu cần tính nhất quán tuyệt đối (Thanh toán, trạng thái, xác thực...).
- REPLICA_PREFERRED: Dành cho các dịch vụ tải đọc cao (Read-heavy) như Cache, tra cứu sản phẩm.
Lưu ý
- Cơ chế Replication của Redis là bất đồng bộ, nghĩa là Slave có thể chưa cập nhật dữ liệu mới nhất kịp thời.
- Có khả năng xảy ra tình trạng stale data (dữ liệu cũ) khi đọc ngay sau khi vừa ghi.
6. Lưu ý khi áp dụng CircuitBreaker
Redis cực kỳ nhanh, vì vậy thông thường không cần áp dụng CircuitBreaker.
Nếu áp dụng:
- Thiết lập failureRateThreshold cao (Ví dụ: 70%).
- Chỉ nên cân nhắc áp dụng cho Read Timeout hoặc luồng Fallback.
- Khuyến nghị áp dụng Breaker cho các yêu cầu Fallback (DB/API) hơn là bản thân Redis.
- Tóm tắt
- Cần tính nhất quán dữ liệu:
ReadFrom.MASTER - Mục đích hiệu năng / Cache:
ReadFrom.REPLICA_PREFERRED - Ứng phó Topology: Lettuce: adaptive + periodic refresh; Redisson: scanInterval.
- Ứng phó MOVED: Cài đặt Client + Kiểm soát thời điểm Resharding.
- Kiểm soát Rebalancing: Chạy lệnh
redis-clithủ công.
Điều quan trọng nhất trong vận hành Redis Cluster là hiểu rằng "con người là chủ thể thay đổi cấu trúc cụm". Chỉ cần cấu hình Client tốt để phát hiện và ứng phó nhanh, các vấn đề về
MOVED hay stale read hầu hết đều có thể kiểm soát được.
Nguồn bài viết ryukato.github.io


