
Danh mục:
Trong bài này, tác giả trình bày cấu trúc, cách hoạt động và ý tưởng thiết kế của một server RAG Embedding tự xây dựng dựa trên FastAPI. Server này sử dụng Qdrant làm vector store và xử lý embedding bằng bất đồng bộ (async) dựa trên dữ liệu thử nghiệm.
Toàn bộ mã nguồn có thể xem tại GitHub: rag_embedding_server.
1. Mục tiêu & Tổng quan dự án
Tại sao lại xây server embedding riêng?
- Cần một server nhẹ, chuyên dụng cho việc embedding chunks văn bản dài
- Có khả năng dùng được mô hình embedding của HuggingFace
- Kiểm soát tốt hơn đồng thời, queue, tốc độ xử lý
- Giảm phụ thuộc vào nhiều thư viện/phần mềm nặng trong các giải pháp mở như LangChain
- Triển khai & vận hành đơn giản hơn
2. Các thành phần chính
1) api.py — FastAPI Endpoint
- Khởi tạo endpoint POST /test/embed
- Dữ liệu đầu vào: danh sách chunks (đoạn văn nhỏ)
- Mỗi chunk được đưa vào queue nội bộ
- Server trả về status "enqueued" với số lượng chunks được xếp hàng
Ví dụ:
@app.post("/test/embed") async def embed_documents(request: TestRagChunkListRequest): for chunk in request.chunks: await embedding_worker.enqueue(chunk) return {"status": "enqueued", "count": len(request.chunks)}
2) embedding_worker.py — Queue & Worker xử lý embedding
- Dùng asyncio.Queue làm queue nội bộ
- Worker chạy liên tục trong background lấy batch từ queue
- Gửi batch cho hàm tạo embedding và lưu kết quả vào repository
Hỗ trợ:
- Throttling (giới hạn tốc độ)
- Parallel task (song song)
- Retry & logging lỗi
Ví dụ pseudo-code worker chính:
class EmbeddingWorker: async def start(self): while True: batch = await self._next_batch() vectors = self.embedding_fn(batch) self.embedding_repository.upsert_many(vectors)
3) embedding_repository.py — Tương tác với Qdrant
- Thực hiện upsert_many(vectors) để đẩy nhiều embedding vào Qdrant
- Schema và collection có thể mở rộng bằng payload_builder.py
- Giúp lưu vector kèm metadata vào vector DB
3. Luồng xử lý tổng thể
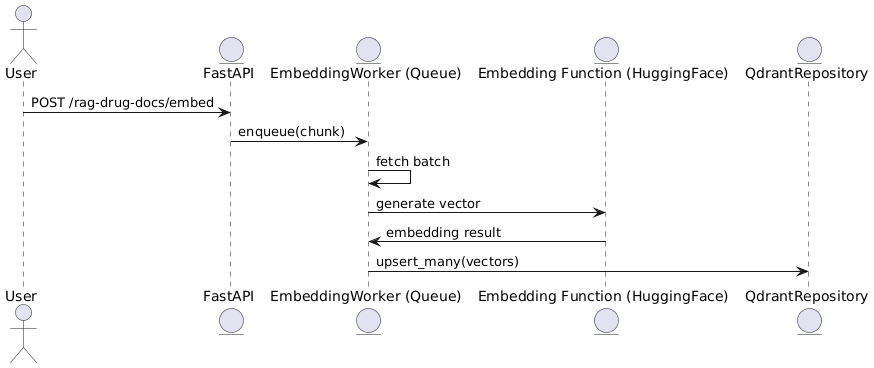
Dưới đây là sơ đồ tổng thể:
User → FastAPI → EmbeddingWorker (queue) → EmbeddingFn (HuggingFace) → Qdrant
- Client gửi request /test/embed gồm list chunks
- FastAPI enqueue chúng vào queue nội bộ
- Worker lấy batch → tạo embedding
- Kết quả vector được upsert vào Qdrant
4. Cách chạy thử tại local
1) Build Docker image
./scripts/build-rag-embedding-server.sh
Chạy từ thư mục gốc có Dockerfile.
2) Chạy container
./scripts/start-rag-embedding-server.sh
Server mặc định chạy ở localhost:8000.
3) Health check
curl http://localhost:8000/test/status
Nếu ổn, API trả về JSON như:
{
"current_task_queue_size": 0,
"max_queue_size": 2000,
"queue_available": true
}
Queue trạng thái này giúp client biết lúc nào gửi thêm request.
4) Gửi request embedding
curl -X POST http://localhost:8000/test/embed \ -H "Content-Type: application/json" \ -d @sample_chunks.json
5. Các bước mở rộng cho server
Bài viết cũng bàn thêm về cách nâng cấp hệ thống khi cần tăng hiệu năng:
1) Round-Robin NGINX load balancing
- Chạy nhiều instance server ở cổng khác nhau
- NGINX phân phối request đến các instance
- Không can thiệp code Python
Nhược điểm: NGINX không biết queue từng instance → khó cân bằng thông minh
2) Celery + Redis phân tán
- FastAPI enqueue vào Redis queue
- Nhiều Celery worker lấy task xử lý song song
- Kết quả có thể trả về callback hoặc lưu DB
- Ưu: chia sẻ queue, retry, monitor…
- Nhược: tăng độ phức tạp vận hành
6. Tóm tắt
Server RAG Embedding này:
- Xử lý embedding bất đồng bộ với queue
- Lưu vector vào Qdrant
- Triển khai nhẹ, dễ mở rộng với Docker / Celery
- Có thể tùy chỉnh mô hình embedding
Nguồn bài viết - Dịch từ ryukato.github.io


