
Danh mục:
1) Vì sao cần Recommendation?
- Tăng tỷ lệ chuyển đổi: khách tìm thấy sản phẩm phù hợp nhanh hơn.
- Tăng giá trị đơn hàng trung bình (AOV) qua cross-sell / up-sell.
- Tăng tỷ lệ quay lại (retention) nhờ trải nghiệm cá nhân hóa.
- Giảm tỷ lệ thoát trang khi khách không tìm thấy gì phù hợp.
- Amazon từng công bố ~ 35% doanh thu đến từ hệ thống recommendation.
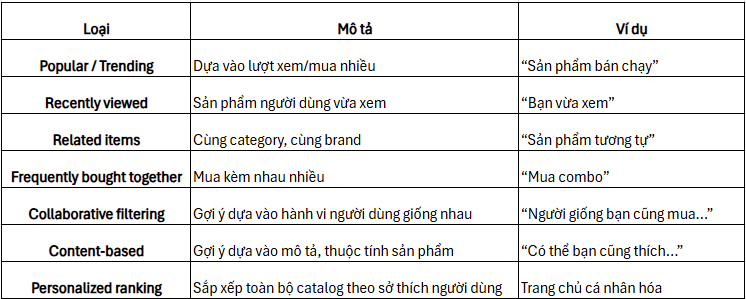
2) Các loại gợi ý phổ biến
3) Kiến trúc tổng quan
[User Event Stream] ─┐
├─> [Feature Store / Data Lake]
[Product Catalog] ───┘
↓
[Offline Training (ML Pipeline)] ← (:contentReference[oaicite:1]{index=1} / :contentReference[oaicite:2]{index=2} / :contentReference[oaicite:3]{index=3})
↓
[Model Registry]
↓
[Online Serving API (Realtime Inference)]
↓
[Recommendation API / BFF]
↓
[Web / App / Email / Ads]
- Thu thập hành vi: click, search, add-to-cart, purchase, rating
- Xây dựng feature: user embedding, product embedding, hành vi thời gian
- Huấn luyện mô hình ML định kỳ (daily / hourly)
- Triển khai mô hình online (latency < 100ms)
4) Thu thập & xử lý dữ liệu hành vi
4.1 Sự kiện cần log
search(query), view(product_id), add_to_cart(product_id), purchase(order_id), wishlist, rating, click_recommendation
4.2 Cách log
Dùng SDK analytics (Segment, Snowplow) → đẩy vào event bus (Kafka)
ETL vào data lake (BigQuery, S3) → tính toán batch
5) Chiến lược gợi ý điển hình
5.1 Collaborative filtering (CF)
- Ý tưởng: “Người giống bạn cũng thích sản phẩm này”
- Dữ liệu đầu vào: ma trận user × item (view/buy/rating)
- Thuật toán: Matrix Factorization (ALS/SVD), Neural CF
- Ưu: cá nhân hóa cao; Nhược: cold-start với user mới
5.2 Content-based filtering
- Dựa trên đặc trưng sản phẩm: category, brand, price, màu, vector TF-IDF từ mô tả
- Tính độ tương đồng cosine → gợi ý sản phẩm tương tự
- Ưu: không cần dữ liệu user; Nhược: ít đa dạng
5.3 Hybrid model
- Kết hợp CF + content-based
- Có thể dùng learning-to-rank (LTR) để học trọng số
Ví dụ: mô hình XGBoost / LightGBM xếp hạng sản phẩm cho mỗi user
6) Triển khai online serving
- Build vector embedding cho user và product
- Lưu vào vector DB (Pinecone / Weaviate / Elasticsearch vector)
- Khi người dùng truy cập, lấy user embedding → tìm top K sản phẩm gần nhất
- Cache top N gợi ý hot/popular vào Redis để trả nhanh
Với user mới chưa có hành vi → fallback sang trending/popular + content-based.
7) Đánh giá & tối ưu
- Offline metrics: Precision@K, Recall@K, MAP, NDCG
- Online: A/B test tỷ lệ click, add-to-cart, conversion
- Điều chỉnh tần suất cập nhật mô hình, thời gian log hành vi, logic diversity (đa dạng danh sách)
8) Vấn đề cần lưu ý
- Cold-start: người dùng/sản phẩm mới → cần fallback logic tốt
- Bias: sản phẩm hot liên tục được gợi ý → dùng re-ranking để đa dạng
- Latency: đảm bảo < 100ms để không ảnh hưởng trang chủ
- Privacy/GDPR: mã hóa ID người dùng, xóa dữ liệu khi user yêu cầu
9) Kết luận
Hệ thống recommendation giúp biến “người xem thành người mua”, và là vũ khí cạnh tranh chủ lực của các sàn e-commerce lớn.
Giai đoạn đầu: dùng rule-based (popular, related)
Khi có data lớn: chuyển sang collaborative + hybrid + learning-to-rank
Kết hợp personalization real-time để tối đa chuyển đổi
Lưu ý: Recommendation là hệ thống “liên tục cải tiến” — càng nhiều data, càng gợi ý chính xác.


