
Chúng ta đang ở một bước ngoặt của trí tuệ nhân tạo (AI). Trong nhiều năm qua, chúng ta chỉ tập trung vào mô hình. Chúng ta tự hỏi mô hình đó thông minh hay tốt đến mức nào; chúng ta kiểm tra các bảng xếp hạng và điểm chuẩn (benchmarks) để xem liệu Mô hình A có đánh bại Mô hình B hay không.
Sự khác biệt giữa các mô hình hàng đầu trên các bảng xếp hạng tĩnh đang dần thu hẹp. Nhưng đây có thể chỉ là một ảo giác. Khoảng cách giữa các mô hình chỉ thực sự rõ ràng khi nhiệm vụ càng kéo dài và càng phức tạp. Điều đó phụ thuộc vào độ bền bỉ (durability): Khả năng một mô hình tuân thủ hướng dẫn tốt đến mức nào khi thực hiện hàng trăm lần gọi công cụ (tool calls) theo thời gian. Sự chênh lệch 1% trên bảng xếp hạng không thể phát hiện được độ tin cậy nếu một mô hình bị "lệch đường ray" sau năm mươi bước thực hiện.
Chúng ta cần một phương thức mới để chứng minh năng lực, hiệu suất và sự cải tiến. Chúng ta cần những hệ thống chứng minh được rằng các mô hình có thể thực hiện các luồng công việc kéo dài nhiều ngày một cách đáng tin cậy. Một câu trả lời cho vấn đề này chính là Agent Harness.
Agent Harness là gì?
Agent Harness là cơ sở hạ tầng bao quanh một mô hình AI để quản lý các tác vụ chạy dài. Bản thân nó không phải là tác nhân (agent). Nó là hệ thống phần mềm quản lý cách thức tác nhân vận hành, đảm bảo tác nhân đó luôn đáng tin cậy, hiệu quả và có thể điều hướng được.
Nó hoạt động ở cấp độ cao hơn các khung phần mềm (framework) dành cho agent thông thường. Trong khi một framework cung cấp các khối xây dựng cho công cụ hoặc thực hiện vòng lặp tác nhân, thì Harness cung cấp các thiết lập sẵn về câu lệnh (prompt), cách xử lý định hướng cho các lần gọi công cụ, các điểm móc vòng đời (lifecycle hooks) hoặc các năng lực sẵn có như lập kế hoạch, truy cập hệ thống tệp hoặc quản lý các tác nhân phụ (sub-agents). Nó không chỉ là một framework; nó là một hệ thống "đã lắp sẵn pin" (đầy đủ mọi thứ để vận hành ngay lập tức).
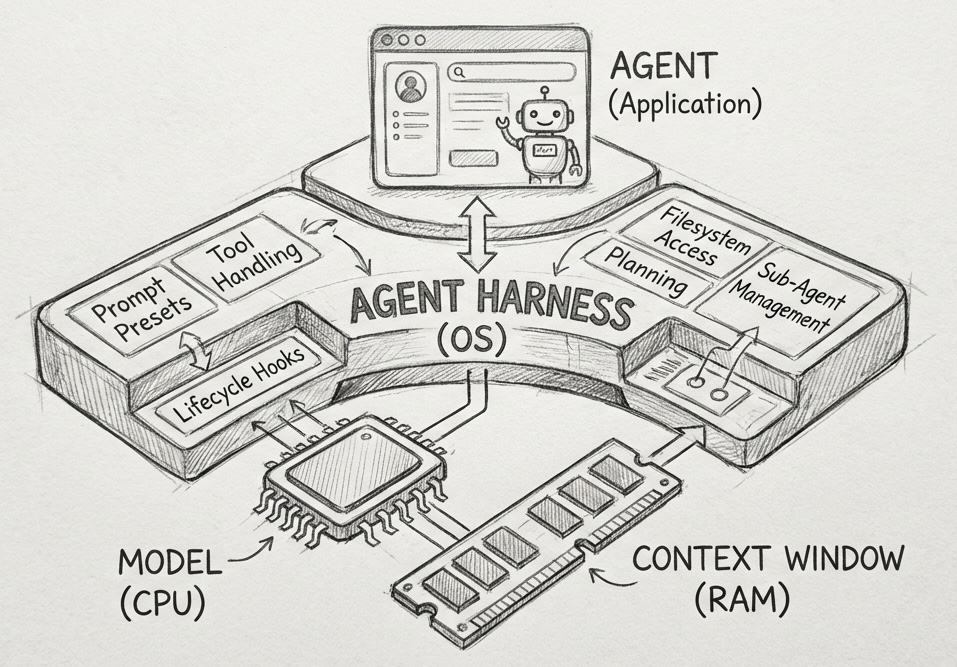
Chúng ta có thể hình dung điều này bằng cách so sánh nó với một chiếc máy tính:
- Mô hình (Model) là CPU: Cung cấp sức mạnh xử lý thô.
- Cửa sổ ngữ cảnh (Context Window) là RAM: Là bộ nhớ làm việc có hạn và dễ biến mất.
- Agent Harness là Hệ điều hành (OS): Nó điều phối ngữ cảnh, xử lý trình tự "khởi động" (câu lệnh, các điểm móc nối) và cung cấp các trình điều khiển tiêu chuẩn (xử lý công cụ).
- Agent là Ứng dụng: Là logic cụ thể của người dùng chạy trên nền hệ điều hành đó.
Agent Harness thực hiện các chiến lược "Kỹ nghệ Ngữ cảnh" (Context Engineering) như giảm thiểu ngữ cảnh thông qua nén dữ liệu, đẩy trạng thái sang bộ lưu trữ, hoặc cô lập các tác vụ vào các tác nhân phụ. Đối với các nhà phát triển, điều này có nghĩa là bạn có thể bỏ qua việc xây dựng hệ điều hành và chỉ tập trung vào ứng dụng, xác định logic độc nhất cho agent của mình.
Hiện tại, các bộ Harness đa năng còn khá hiếm. Claude Code là một ví dụ điển hình cho danh mục mới nổi này, đang cố gắng tiêu chuẩn hóa với Claude Agent SDK hoặc LangChain DeepAgents. Tuy nhiên, có thể tranh luận rằng tất cả các CLI lập trình (giao diện dòng lệnh) xét theo một cách nào đó đều là các bộ harness chuyên biệt được thiết kế cho các lĩnh vực cụ thể.
Vấn đề của các bảng xếp hạng (Benchmarks) và nhu cầu về Agent Harness
Trước đây, các bảng xếp hạng hầu hết dựa trên đầu ra của mô hình qua một lượt phản hồi duy nhất. Năm ngoái, chúng ta bắt đầu thấy xu hướng đánh giá toàn bộ hệ thống thay vì chỉ mô hình thô, trong đó mô hình là một thành phần có thể sử dụng công cụ hoặc tương tác với môi trường (ví dụ: AIMO, SWE-Bench).
Những bảng xếp hạng mới này gặp khó khăn trong việc đo lường độ tin cậy. Chúng hiếm khi kiểm tra cách mô hình hành xử sau lần gọi công cụ hoặc lượt tương tác thứ 50 hoặc 100. Đây chính là nơi khó khăn thực sự nảy sinh. Một mô hình có thể đủ thông minh để giải một câu đố hóc búa trong một hoặc hai lần thử, nhưng lại thất bại trong việc tuân thủ các hướng dẫn ban đầu hoặc suy luận sai về các bước trung gian sau khi chạy được một giờ. Các bảng xếp hạng tiêu chuẩn khó có thể nắm bắt được độ bền bỉ cần thiết cho các quy trình làm việc dài hơi.
Khi các bảng xếp hạng trở nên phức tạp hơn, chúng ta cần thu hẹp khoảng cách giữa những tuyên bố trên bảng xếp hạng và trải nghiệm thực tế của người dùng. Một bộ Agent Harness trở nên thiết yếu vì ba lý do quan trọng:
- Xác thực tiến trình thực tế: Các bảng xếp hạng đang không khớp với nhu cầu người dùng. Khi các mô hình mới được phát hành thường xuyên, Harness cho phép người dùng dễ dàng kiểm tra và so sánh hiệu suất của chúng dựa trên các trường hợp sử dụng và hạn chế thực tế của chính họ.
- Nâng tầm trải nghiệm người dùng: Nếu không có Harness, trải nghiệm người dùng có thể thấp hơn tiềm năng của mô hình. Việc phát hành Harness cho phép nhà phát triển xây dựng Agent bằng các công cụ và quy trình chuẩn đã được chứng minh, đảm bảo người dùng đang tương tác với cùng một cấu trúc hệ thống.
- Cải tiến dựa trên phản hồi thực tế (Hill Climbing): Một môi trường chung và ổn định (Harness) tạo ra một vòng lặp phản hồi, nơi các nhà nghiên cứu có thể lặp lại và cải thiện các bài kiểm tra dựa trên sự chấp nhận thực tế của người dùng.
Khả năng cải thiện một hệ thống tỷ lệ thuận với việc bạn có thể xác minh đầu ra của nó dễ dàng đến mức nào.
Một bộ Harness biến các quy trình làm việc mơ hồ, đa bước của Agent thành dữ liệu có cấu trúc mà chúng ta có thể ghi nhật ký (log) và chấm điểm, cho phép chúng ta cải tiến hệ thống một cách hiệu quả.
"Bài học đắng cay" (Bitter Lesson) khi xây dựng Agent
Rich Sutton đã viết một bài luận mang tên The Bitter Lesson. Ông lập luận rằng các phương pháp tổng quát tận dụng sức mạnh tính toán luôn đánh bại những kiến thức do con người tự lập trình (hand-coded) trong mọi trường hợp. Chúng ta đang thấy bài học này lặp lại trong quá trình phát triển Agent hiện nay:
- Manus đã tái cấu trúc Harness của họ 5 lần trong 6 tháng để loại bỏ các giả định cứng nhắc.
- LangChain đã thiết kế lại Agent "Open Deep Research" của họ 3 lần chỉ trong một năm.
- Vercel đã loại bỏ 80% công cụ của Agent, dẫn đến ít bước hơn, ít token hơn và phản hồi nhanh hơn.
Để vượt qua "Bài học đắng cay" này, cơ sở hạ tầng (Harness) của chúng ta phải nhẹ nhàng. Mỗi phiên bản mô hình mới sẽ có một cách tối ưu khác nhau để cấu trúc Agent. Những năng lực từng đòi hỏi các quy trình lập trình thủ công phức tạp vào năm 2024 giờ đây đã có thể xử lý chỉ bằng một câu lệnh trong cửa sổ ngữ cảnh vào năm 2026.
Các nhà phát triển phải xây dựng các bộ Harness cho phép họ "khai tử" những logic thông minh mà họ vừa viết ngày hôm qua. Nếu bạn thiết kế quá mức (over-engineer) luồng kiểm soát, bản cập nhật mô hình tiếp theo sẽ phá hỏng hệ thống của bạn.
Điều gì sẽ đến tiếp theo?
Chúng ta đang tiến tới sự hội tụ giữa môi trường huấn luyện và môi trường suy luận. Điểm nghẽn mới sẽ là độ bền bỉ của ngữ cảnh. Harness sẽ trở thành công cụ chính để giải quyết vấn đề "lệch mô hình" (model drift). Các phòng thí nghiệm sẽ sử dụng Harness để phát hiện chính xác thời điểm mô hình ngừng tuân thủ hướng dẫn hoặc suy luận sai sau bước thứ 100. Dữ liệu này sẽ được đưa trực tiếp ngược lại quá trình huấn luyện để tạo ra các mô hình không bị "mệt mỏi" trong các tác vụ dài.
Với tư cách là những người xây dựng và phát triển, trọng tâm nên thay đổi:
- Bắt đầu đơn giản: Đừng xây dựng các luồng kiểm soát khổng lồ. Hãy cung cấp các công cụ nguyên tử mạnh mẽ. Hãy để mô hình tự lập kế hoạch. Hãy triển khai các rào chắn (guardrails), cơ chế thử lại và xác thực.
- Xây dựng để xóa bỏ: Hãy làm cho kiến trúc của bạn có tính mô-đun. Các mô hình mới sẽ thay thế logic của bạn. Bạn phải sẵn sàng để gỡ bỏ mã nguồn cũ.
- Harness chính là Tập dữ liệu: Lợi thế cạnh tranh không còn nằm ở câu lệnh (prompt) nữa. Nó nằm ở các "quỹ đạo" (trajectories) mà Harness của bạn ghi lại được. Mỗi lần Agent thất bại trong việc tuân thủ hướng dẫn ở giai đoạn cuối của quy trình đều có thể được sử dụng để huấn luyện phiên bản tiếp theo.
Nguồn bài viết dịch từ Tác giả Phil Schmid


