
Không phải là "Ảo giác AI" nếu nó thực sự hoạt động
Trước khi viết bài blog về cách tôi sử dụng LLM, tôi từng viết một bài mang tính châm biếm có tiêu đề: "Liệu LLM có thể viết code tốt hơn nếu bạn cứ liên tục yêu cầu chúng 'viết code tốt hơn'?". Đó là một thử nghiệm để xác định cách LLM diễn giải câu lệnh mơ hồ "viết code tốt hơn": trong trường hợp đó, nó ưu tiên làm cho mã nguồn trở nên phức tạp hơn với nhiều tính năng hữu ích hơn. Nhưng nếu thay bằng các câu lệnh tối ưu hóa mã nguồn, nó thực sự đã làm cho code chạy nhanh hơn thành công, dù cái giá phải trả là sự sụt giảm đáng kể về khả năng đọc hiểu (readability).
Trong kỹ nghệ phần mềm, một trong những "tội lỗi" lớn nhất là tối ưu hóa sớm (premature optimization) — nơi bạn hy sinh khả năng đọc và bảo trì code để chạy theo những cải thiện hiệu suất vốn làm chậm thời gian phát triển và có thể không đáng để đánh đổi. Nhưnnnnng với lập trình bằng agent, chúng ta mặc định chấp nhận rằng cách chúng ta hiểu code là một sự mờ nhạt (fuzzy): liệu việc để agent liên tục áp dụng các tối ưu hóa với mục đích duy nhất là giảm thiểu thời gian chạy benchmark — từ đó tạo ra code nhanh hơn trong các trường hợp sử dụng thực tế nếu các benchmark đó mang tính đại diện — giờ đây có thực sự là một ý tưởng hay? Mọi người thường phàn nàn về việc code do AI tạo ra chạy chậm, nhưng nếu AI hiện nay có thể tạo ra code nhanh một cách đáng tin cậy, điều đó sẽ thay đổi hoàn toàn cuộc tranh luận.
Với tư cách là một nhà khoa học dữ liệu, tôi thấy khá nản lòng khi vài năm qua chẳng có công cụ khoa học dữ liệu mới nào thực sự đột phá cho Python ngoài polars. Không có gì ngạc nhiên khi các nghiên cứu về AI và LLM đã "thâu tóm" các nghiên cứu DS truyền thống, nơi những bước tiến như text embeddings (nhúng văn bản) đã mang lại những lợi ích cực kỳ giá trị cho các tác vụ xử lý ngôn ngữ tự nhiên thông thường trong khoa học dữ liệu. Các thuật toán máy học truyền thống vẫn còn giá trị, nhưng chưa ai phát minh ra phiên bản "Gradient Boosted Decision Trees 2". Thêm vào đó, là một nhà khoa học dữ liệu tại San Francisco, tôi bị "buộc" phải dùng MacBook, nhưng lại chẳng có tiện ích khoa học dữ liệu nào thực sự tận dụng được GPU trên chip Apple Silicon vì chúng không hỗ trợ Metal API; các công cụ DS hiện nay hầu như chỉ dành riêng cho CUDA trên các dòng GPU của NVIDIA. Sẽ ra sao nếu các agent giờ đây có thể chuyển đổi (port) các thuật toán này để: a) chạy trên Rust với các bản cài đặt Python để hưởng lợi về tốc độ và b) chạy trên GPU mà không cần các thư viện phụ thuộc phức tạp?
Tháng này, OpenAI đã công bố ứng dụng Codex của họ và các đồng nghiệp của tôi bắt đầu đặt câu hỏi. Thế là tôi tải nó về, và để thử nghiệm mô hình GPT-5.2-Codex (high), tôi đã yêu cầu nó triển khai lại thuật toán UMAP bằng Rust. UMAP là một kỹ thuật giảm chiều dữ liệu, có thể tiếp nhận một ma trận dữ liệu đa chiều, sau đó vừa thực hiện phân cụm vừa trực quan hóa dữ liệu đó trong không gian ít chiều hơn. Tuy nhiên, đây là một thuật toán cực kỳ tốn tài nguyên tính toán và công cụ duy nhất có thể xử lý nó nhanh chóng là cuML của NVIDIA — thứ vốn đòi hỏi một "địa ngục" các thư viện phụ thuộc CUDA. Nếu tôi có thể tạo ra một gói UMAP bằng Rust siêu nhanh với các thư viện phụ thuộc tối thiểu, đó sẽ là một bước nhảy vọt về năng suất cho loại công việc tôi đang làm và mở ra những ứng dụng thú vị nếu tốc độ đủ nhanh.
Sau khi OpenAI phát hành GPT-5.3-Codex (high) — phiên bản hoạt động tốt hơn và nhanh hơn đáng kể trong các loại tác vụ này so với GPT-5.2-Codex — tôi đã yêu cầu Codex viết một bản triển khai UMAP từ con số 0 bằng Rust. Nhìn thoáng qua, nó có vẻ hoạt động tốt và cho kết quả hợp lý. Tôi cũng chỉ thị cho nó tạo ra các bài kiểm tra hiệu năng (benchmarks) để thử nghiệm trên nhiều kích thước ma trận đầu vào mang tính đại diện. Rust có một thư viện benchmark phổ biến là criterion, nó xuất kết quả dưới định dạng rất dễ đọc và quan trọng nhất là các agent có thể dễ dàng phân tích được.
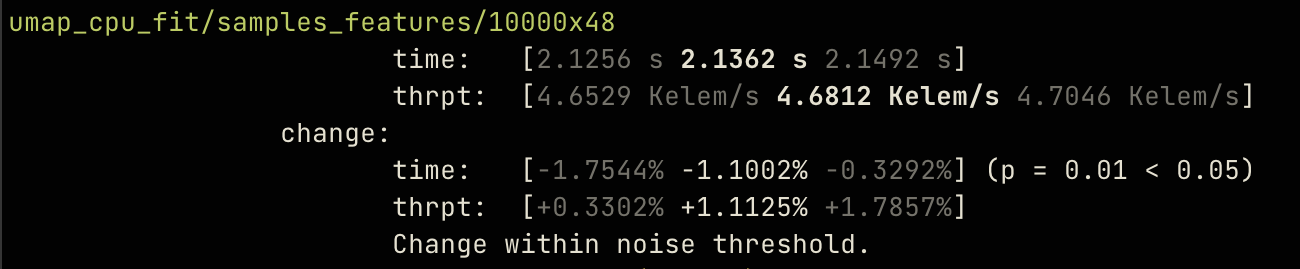
Nhìn thoáng qua, các bài kiểm tra hiệu năng (benchmarks) và cách chúng được xây dựng trông rất ổn (nghĩa là không có sự gian lận) và tốc độ nhanh hơn nhiều so với việc chạy UMAP bằng Python. Để kiểm tra sâu hơn, tôi đã yêu cầu các agent triển khai thêm các thuật toán máy học hữu ích khác như HDBSCAN thành các dự án riêng biệt, với mỗi kho lưu trữ (repo) đều bắt đầu bằng kế hoạch gồm 8 câu lệnh (prompt) theo trình tự sau:
- Triển khai gói thư viện với các yêu cầu chức năng và mục tiêu thiết kế cụ thể; sau đó, tạo các benchmark với kích thước ma trận đặc trưng cho các tình huống sử dụng thực tế.
- Thực hiện lượt rà soát thứ hai để dọn dẹp mã nguồn/chú thích và thực hiện các tối ưu hóa sâu hơn.
- Quét toàn bộ thư viện (crate) để tìm ra các điểm yếu về thuật toán trong các trường hợp cực đoan, viết một câu cho mỗi điểm yếu để mô tả vấn đề, giải pháp tiềm năng và định lượng tác động của giải pháp đó.
- Tận dụng các phát hiện trên để tối ưu hóa thư viện sao cho TẤT CẢ các benchmark chạy nhanh hơn 60% (tức tốc độ gấp 1.4 lần). Sử dụng bất kỳ kỹ thuật nào để đạt được điều đó và lặp lại cho đến khi hiệu năng benchmark hội tụ, nhưng không được "gian lận" benchmark bằng cách ép khớp (overfitting) riêng trên dữ liệu đầu vào của bài kiểm tra.
- Tạo các cấu hình tinh chỉnh (tuning profiles) tùy chỉnh tận dụng các đặc tính nội tại của dữ liệu đầu vào và độ bão hòa luồng CPU/lập lịch/song song hóa để tối ưu hóa thư viện sao cho TẤT CẢ các benchmark chạy nhanh hơn 60% (tốc độ gấp 1.4 lần). Có thể sử dụng thư viện flamegraph để hỗ trợ phân tích hiệu năng.
- Thêm các cầu nối Python sử dụng pyo3 phiên bản 0.27.2 và maturin, kèm theo các ràng buộc cụ thể cho từng gói (việc chỉ định phiên bản pyo3 là cần thiết để đảm bảo tương thích với Python 3.10+).
- Tạo các benchmark tương ứng trong Python và viết một script so sánh giữa bản cài đặt Python này với một gói Python hiện có.
- Buộc tội agent rằng nó có khả năng đã "gian lận" trong việc triển khai thuật toán khi theo đuổi các tối ưu hóa, từ đó yêu cầu nó tối ưu hóa dựa trên độ tương đồng của kết quả đầu ra so với một bản triển khai chuẩn đã biết (ví dụ: với tác vụ hồi quy, hãy giảm thiểu sai số tuyệt đối trung bình - MAE trong dự đoán giữa hai phương pháp).
Các ràng buộc đồng thời về yêu cầu chất lượng mã nguồn thông qua AGENTS.md, yêu cầu tốc độ với mục tiêu định lượng được, và yêu cầu về độ chính xác/chất lượng đầu ra, tất cả đều thực sự giúp tìm ra những cải thiện tốc độ có ý nghĩa một cách nhất quán (ít nhất là nhanh gấp 2 đến 3 lần).
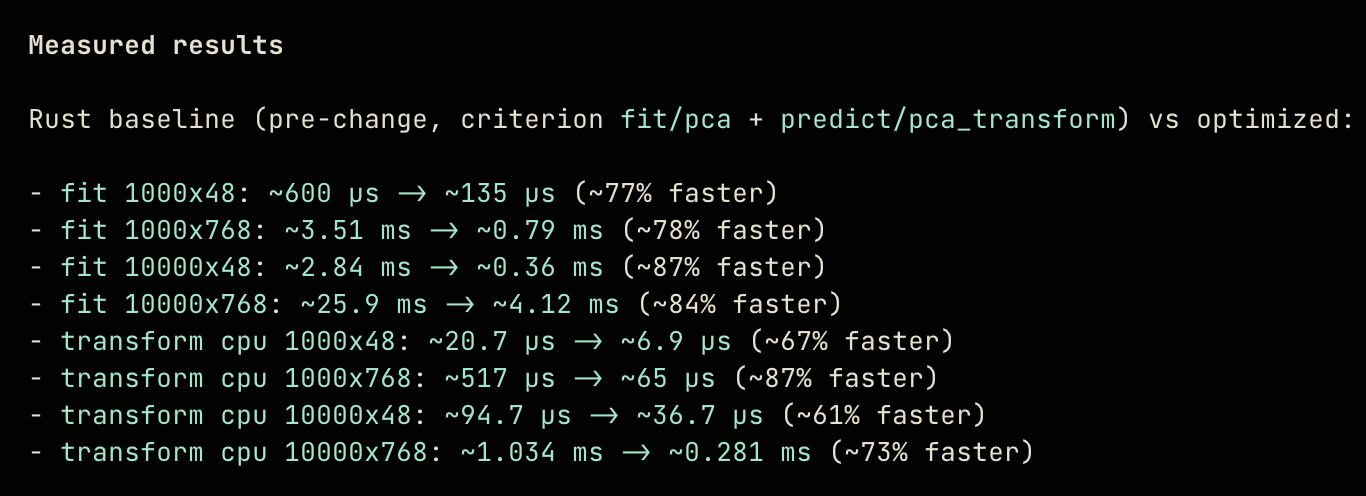
Tôi không hài lòng với việc chỉ nhanh hơn 2-3 lần: ngày nay, để mã nguồn do agent tạo ra có ý nghĩa thực sự chứ không chỉ là một kho lưu trữ khác trên GitHub, nó phải là bản triển khai nhanh nhất có thể. Trong một phút tò mò đầy mỉa mai, tôi đã thử xem liệu Codex và Opus có các phương pháp tối ưu hóa code Rust khác nhau hay không bằng cách kết nối chúng lại:
- Yêu cầu Codex tối ưu hóa các bài kiểm tra hiệu năng (benchmarks) xuống còn 60% thời gian chạy.
- Yêu cầu Opus tiếp tục tối ưu hóa các bài kiểm tra đó xuống còn 60% thời gian chạy nữa.
- Yêu cầu Opus giảm thiểu sự khác biệt giữa bản triển khai của agent và bản triển khai chuẩn đã biết mà không làm giảm quá 5% tốc độ trên bất kỳ bài kiểm tra nào.
Cách này thực sự hiệu quả. Từ các thử nghiệm của tôi với các thuật toán, Codex thường có thể tăng tốc thuật toán lên 1,5–2 lần, sau đó bằng cách nào đó Opus lại tăng tốc đoạn code đã tối ưu đó thêm một mức độ lớn hơn nữa. Điều này đúng với tất cả các mã nguồn Rust tôi đã thử nghiệm: tôi cũng đã chạy quy trình này cho icon-to-image và các thư viện đám mây từ ngữ, kết quả là tốc độ tăng tổng cộng gấp 6 lần ở cả hai thư viện.
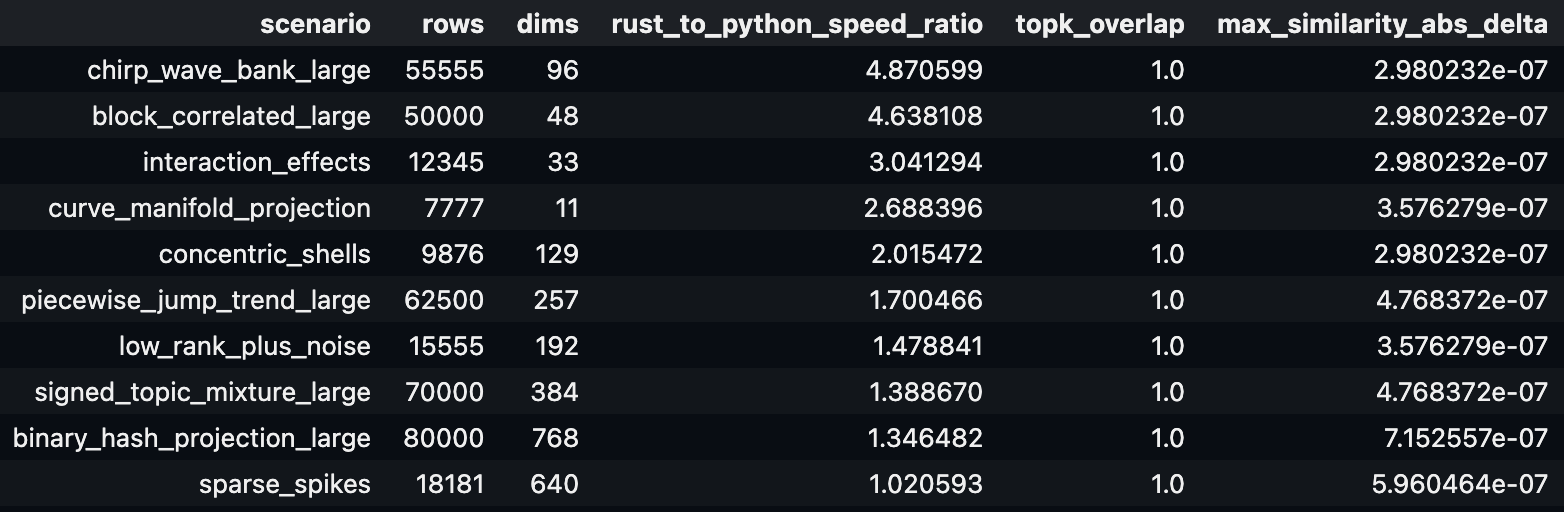
Liệu những bản triển khai được tối ưu cực hạn bởi agent (agent-benchmaxxed) này có thực sự đánh bại được các thư viện thuật toán máy học hiện có, dù các thư viện đó vốn đã được viết bằng các ngôn ngữ bậc thấp như C/C++/Fortran? Dưới đây là kết quả trên chiếc MacBook Pro cá nhân của tôi khi so sánh benchmark CPU của các bản triển khai Rust cho nhiều thuật toán ML nặng với các bản triển khai phổ biến tương ứng (trong đó kết quả Rust của agent nằm trong sai số cho phép so với bản chuẩn, và các gói Python được so sánh với bản cài đặt Python của các gói Rust do agent viết):
- UMAP: Nhanh hơn 2–10 lần so với fast-umap của Rust, nhanh hơn 9–30 lần so với umap của Python.
- HDBSCAN (thuật toán phân cụm): Nhanh hơn 23–100 lần so với thư viện hdbscan của Rust, nhanh hơn 3–10 lần so với hdbscan của Python.
- GBDT (thuật toán tăng cường cây): Tốc độ huấn luyện/dự đoán nhanh hơn 1,1–1,5 lần so với thư viện treeboost của Rust, nhanh hơn 24–42 lần khi huấn luyện và 1–5 lần khi dự đoán so với xgboost của Python.
Tôi chắc chắn sẽ chấp nhận những kết quả đó với một quy trình viết prompt chưa hề được tối ưu này! Trong mọi trường hợp, các bài kiểm tra GPU không ngạc nhiên khi còn cho kết quả tốt hơn nữa; với wgpu và các shader WGSL bổ sung, mã nguồn chạy được trên Metal mà không cần thêm bất kỳ thư viện phụ thuộc nào, tuy nhiên cần thử nghiệm thêm nên tôi chưa thể công bố các con số cụ thể ngay lúc này.
Mặc dù tôi có thể đẩy các thư viện mới này lên GitHub ngay bây giờ, nhưng các thuật toán máy học là một lĩnh vực đòi hỏi sự cẩn trọng và kiểm thử cực kỳ khắt khe. Sẽ thật ngạo mạn nếu định chuyển đổi (port) scikit-learn của Python — tiêu chuẩn vàng của các thư viện khoa học dữ liệu và máy học — sang Rust với tất cả các tính năng đi kèm.
Nhưng đó thực sự là một ý tưởng hay, nên tôi quyết định cứ thử làm xem sao. Với sự trợ giúp của các agent, tôi hiện đang phát triển rustlearn (một cái tên tạm thời), một thư viện Rust không chỉ triển khai các thuật toán máy học tiêu chuẩn tốc độ cao như hồi quy logistic và phân cụm k-means, mà còn bao gồm các bản triển khai nhanh của các thuật toán nêu trên. Quy trình ba bước tôi mô tả ở trên vẫn hoạt động hiệu quả ngay cả với các thuật toán đơn giản hơn để đánh bại các bản triển khai của scikit-learn. Thư viện này nhờ đó có thể nhận các bản cài đặt Python và thậm chí mở rộng sang Web/JavaScript và xa hơn nữa. Điều này cũng cho tôi cơ hội thêm các tính năng cải thiện trải nghiệm sử dụng để giải quyết những phiền toái mà tôi từng phải chịu đựng khi làm nhà khoa học dữ liệu, chẳng hạn như tuần tự hóa mô hình và tích hợp trực tiếp với DataFrame của pandas/polars. Tôi hy vọng trường hợp sử dụng này được coi là thực tế và phức tạp hơn việc làm một ứng dụng terminal mô phỏng vật lý bóng nảy.
Nhiều người đọc đến đây sẽ cho rằng những chỉ số cải thiện hiệu suất này là nhảm nhí, và thành thật mà nói, điều đó cũng hợp lý thôi. Bản thân tôi cũng từng nghĩ các agent sẽ vấp ngã một cách nực cười khi cố gắng làm việc này, nhưng chúng thì không. Để chứng minh rằng tôi không nói khoác, tôi cũng quyết định phát hành một dự án Rust-với-Python đơn giản hơn vào hôm nay: nndex, một "kho" lưu trữ vector trong bộ nhớ được thiết kế để truy xuất các láng giềng gần nhất chính xác nhanh nhất có thể (và cũng có tính năng tìm kiếm gần đúng nhanh), hiện đã có sẵn mã nguồn mở trên GitHub. Nó tận dụng tích vô hướng (dot product) — một trong những phép toán ma trận đơn giản nhất và do đó đã được tối ưu hóa cực mạnh bởi các thư viện hiện có như numpy của Python... vậy mà sau vài lượt tối ưu hóa, nó đã ngang ngửa với numpy dù numpy tận dụng các thư viện BLAS để đạt hiệu suất toán học tối đa. Lẽ dĩ nhiên, tôi đã yêu cầu Opus thêm hỗ trợ cho BLAS cùng với nhiều lượt tối ưu hóa hơn, và giờ đây nó nhanh gấp 1,5 lần tốc độ của numpy trong trường hợp truy vấn đơn lẻ và nhanh hơn nhiều khi dự đoán theo lô (batch prediction). Nó nhanh đến mức mặc dù tôi đã thêm hỗ trợ GPU để thử nghiệm, nhưng việc dùng GPU hầu như không hiệu quả nếu dưới 100.000 hàng, do chi phí điều phối GPU (dispatch overhead) còn lớn hơn cả tốc độ truy xuất thực tế.
Một trong những lời chỉ trích về code do AI tạo ra là nó "chỉ nhai lại mọi thứ trên GitHub". Nhưng về mặt logic, nếu đoạn code đó chạy nhanh hơn bất kỳ thứ gì hiện có, thì nó không thể là đồ đi ăn cắp mà phải là một cách tiếp cận nguyên bản. Ngay cả khi bản chất phụ thuộc vào agent của rustlearn khiến việc áp dụng nó vào các hệ thống hạ nguồn trở nên rủi ro, thì những bài học về cách nó đạt được tốc độ cực hạn đó vẫn vô cùng giá trị.
Hệ lụy từ những thành công với Agent của tôi
Giống như nhiều người đã "lên tàu" agent sau thời Opus 4.5, tôi đã trở nên khá hư vô trong vài tháng qua, nhưng không phải theo những cách thông thường. Thực tế, tôi không hề bị kiệt sức (burnout) và cũng không lo ngại kỹ năng lập trình của mình bị thui chột do dùng agent. Ngược lại, các giới hạn phiên sử dụng (nhằm giãn cách lưu lượng máy chủ) đã vô tình giúp tôi hình thành thói quen lập trình giải trí một giờ mỗi ngày để thử nghiệm và triển khai các ý tưởng mới. Tuy nhiên, liệu việc tôi viết bài blog này và phát triển các thư viện này có ý nghĩa gì không, nếu mọi người có thể sẽ chỉ phản hồi kiểu "dài quá ngại đọc, toàn rác AI" và "code bằng AI thì mặc định là tệ"?
Điều thực sự khó chịu về Opus 4.6 hay Codex 5.3 là bạn không thể tuyên bố công khai rằng "Opus 4.5 (và các mô hình sau đó) tốt hơn gấp bội so với các LLM lập trình ra mắt chỉ vài tháng trước" mà không nghe giống như một kẻ đang "lùa gà" hay giật tít câu view. Nhưng đó lại là sự thật trái ngược với trực giác và cũng là nỗi thất vọng của cá nhân tôi. Tôi đã cố gắng "phá" mô hình chết tiệt này bằng cách đưa cho nó những nhiệm vụ phức tạp mà với trình độ lập trình của mình, tôi cũng phải mất hàng tháng trời mới xong, vậy mà Opus và Codex vẫn cứ làm đúng. Trên Hacker News, tôi từng bị cáo buộc là giật tít khi đưa ra nhận định tương tự, kèm theo những lời buộc tội kiểu: "Tôi dùng Opus 4.5 có thấy hiệu quả đâu, chắc chắn ông đang nói dối". Cách duy nhất để đối phó với sự hoài nghi này là cung cấp thêm nhiều bằng chứng cùng các biện pháp kiểm chứng chặt chẽ hơn, nhưng bạn có thể làm gì nếu người ta nhất quyết không tin vào bằng chứng của bạn?
Một năm trước, tôi là một trong những kẻ hoài nghi và cực kỳ cảnh giác với sự cường điệu về agent, nhưng tôi sẵn sàng thay đổi quan điểm trước những bằng chứng và trải nghiệm mới — điều mà hóa ra lại khá hiếm thấy. Các cuộc thảo luận về AI tạo sinh đã trở nên quá độc hại và luôn kết thúc theo cùng một kịch bản, vì vậy tôi đang thử nghiệm việc "đi chạm cỏ" (rời xa mạng xã hội) thay vào đó, và nó khá dễ chịu. Tại thời điểm này, nếu tôi không tự tin rằng mình có thể làm hài lòng bất cứ ai bằng cách sử dụng AI, thì tôi sẽ tìm thấy niềm an ủi trong việc làm hài lòng chính mình. Tiếp tục mở mã nguồn các dự án, viết blog, và cứ để mọi thứ diễn ra tự nhiên.
Tạm gác lại những phút giây nội tâm, tôi không chắc tương lai sẽ ra sao đối với agent và AI tạo sinh. Việc sử dụng agent của tôi đã chứng minh được tiện ích đáng kể (ít nhất là cho chính tôi) và tôi có thừa các dự án tầm cỡ đang ấp ủ để bận rộn trong vài tháng tới. Mặc dù chắc chắn tôi sẽ dùng LLM nhiều hơn cho các ứng dụng lập trình cần tối ưu hóa, nhưng điều đó không có nghĩa là tôi sẽ dùng LLM nhiều hơn ở các mảng khác: tôi vẫn không dùng LLM để viết lách — thực tế, tôi đã cố tình làm cho giọng văn của mình trở nên châm biếm hơn để đặc biệt phòng tránh những cáo buộc dùng AI.
Đối với Rust, việc làm việc với các agent và quan sát cách chúng đưa ra quyết định hoặc tạo các bản vá (diffs) thực sự đã giúp tôi thoát khỏi "vũng lầy" Rust trung cấp và dạy tôi rất nhiều về hệ sinh thái này thông qua các dự án tham vọng hơn. Mặc dù về mặt kỹ thuật, tôi đã phát hành các gói Rust nhận được nhiều sao trên GitHub, tôi không có ý định ghi Rust vào kỹ năng chuyên môn trên LinkedIn hay CV của mình. Tiện thể nói về CV, chúng sẽ hoạt động thế nào trong một thế giới lập trình bằng agent? Liệu dòng chữ "Đã viết nhiều thư viện mã nguồn mở thông qua AI agent, giúp tăng hiệu suất các thuật toán khoa học dữ liệu/máy học lên gấp nhiều lần" có khiến tôi bị loại trong mắt nhà tuyển dụng vì họ nghĩ tôi đang gian lận và giả mạo năng lực không?
Nghĩa vụ của một lập trình viên chuyên nghiệp là làm những gì hiệu quả nhất, đặc biệt là với mã nguồn mở mà người khác sẽ sử dụng. Agent chỉ là một công cụ khác trong hộp công cụ đó với những ưu và nhược điểm riêng. Nếu bạn từng có trải nghiệm tệ với agent trước tháng 11 năm ngoái, tôi thực sự khuyên bạn nên thử lại một lần nữa với các agent hiện đại, đặc biệt là với một tệp AGENTS.md được thiết kế riêng cho lĩnh vực lập trình và các sắc thái cụ thể của bạn.
Nhìn chung, tôi cảm thấy rất buồn về thực trạng thảo luận quanh vấn đề agent, nhưng cũng rất hào hứng trước những hứa hẹn của nó: hiện tại tôi không rõ cảm xúc nào đang chiếm ưu thế hơn.
Chú thích của tác giả:
Có hai cách tinh vi mà agent có thể làm ảnh hưởng tiêu cực đến kết quả benchmark mà không bị coi là gian lận: a) triển khai một dạng bộ nhớ đệm (caching) khiến các bài kiểm tra benchmark không còn độc lập và b) chạy các benchmark song song trên cùng một hệ thống. Cuối cùng tôi đã thêm các quy tắc vào AGENTS.md để ngăn chặn cả hai trường hợp này.
Thư viện treeboost từng đánh bại thư viện GBT đã tối ưu bằng agent của tôi gấp 4 lần trong bài kiểm tra đầu tiên, điều này rõ ràng đã chạm tự ái của tôi: tôi yêu cầu Opus 4.6: "Hãy tối ưu hóa thư viện sao cho rust_gbt thắng trong TẤT CẢ các bài benchmark trước treeboost." Và nó đã làm đúng như vậy.
Hiện tại, chỉ bản dựng cho macOS mới hỗ trợ BLAS vì hỗ trợ BLAS trên Win/Linux là một "hang thỏ" cần nhiều thời gian nghiên cứu hơn. Trên các nền tảng đó, numpy vẫn thắng, nhưng điều đó sẽ không kéo dài lâu đâu!
Nguồn bài viết từ Tác giả Minimaxir


