
Việc xây dựng các tác nhân AI (AI agents) có khả năng "nhìn" thực thụ đòi hỏi nhiều hơn là chỉ việc truyền hình ảnh vào các câu lệnh (prompts). Các tác nhân lập trình cần đọc ảnh chụp màn hình của giao diện người dùng (UI) mà chúng đang xây dựng. Các tác nhân điều khiển máy tính cần chụp và phân tích ảnh màn hình trình duyệt. Các tác nhân nghiên cứu lại cần xử lý các biểu đồ và sơ đồ từ tài liệu.
Gọi hàm đa phương thức (Multimodal function calling) cho phép các công cụ trả về hình ảnh mà mô hình có thể xử lý một cách tự nhiên (natively), tương tự như cách bạn truyền hình ảnh trong các câu lệnh. Thay vì phải mô tả nội dung có trong một tệp tin, công cụ của bạn sẽ trả về hình ảnh thực tế và Gemini 3 sẽ xử lý nó một cách trực tiếp.
Hướng dẫn này sẽ cho bạn thấy cách thức hoạt động của Gọi hàm đa phương thức thông qua Interactions API. Interactions API là một giao diện thống nhất để tương tác với các mô hình và tác nhân Gemini. Nó đơn giản hóa việc quản lý trạng thái và điều phối công cụ, giúp việc xây dựng các quy trình tác nhân (agentic workflows) nhiều lượt trở nên dễ dàng hơn.
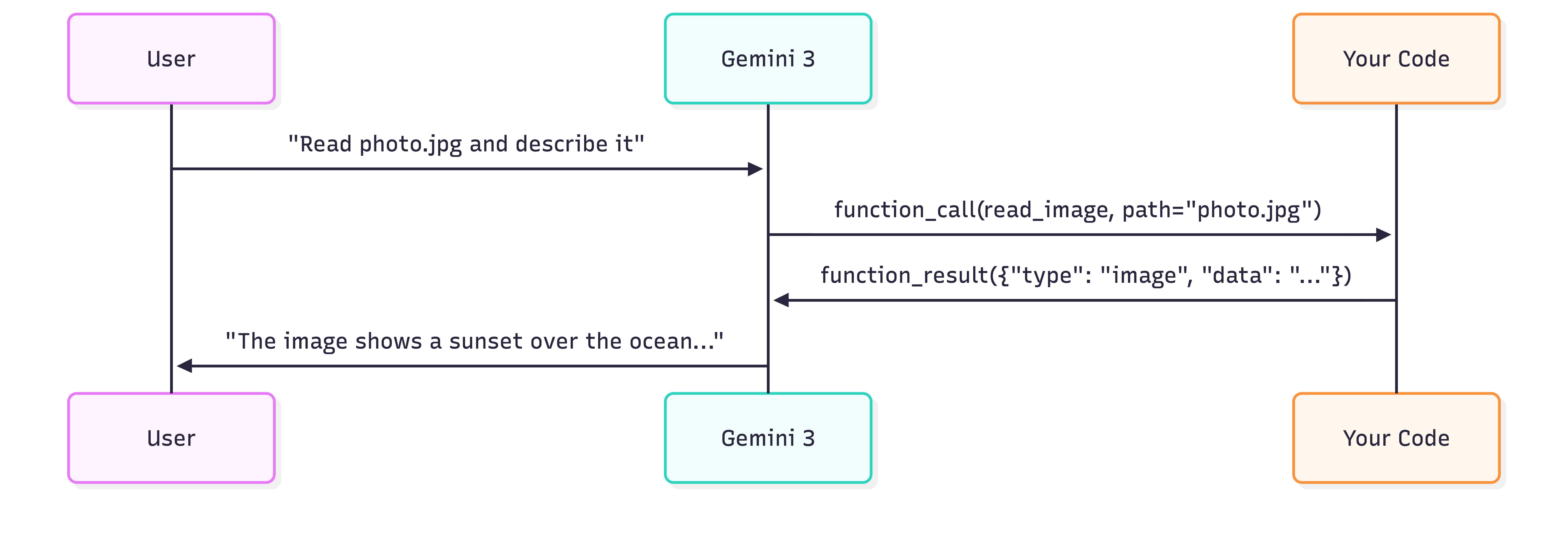
Điểm khác biệt then chốt so với việc gọi hàm tiêu chuẩn nằm ở chỗ
function_result sẽ trả về dữ liệu hình ảnh thực tế. Gemini 3 xử lý nội dung này một cách trực tiếp—mô tả hình ảnh, phân tích tài liệu hoặc sử dụng thông tin hình ảnh để đưa ra quyết định.
{
"type": "function_result",
"call_id": "abc123",
"name": "read_image",
"result": [
{"type": "text", "text": "Bối cảnh bổ sung..."},
{"type": "image", "data": "<base64>", "mime_type": "image/png"}
]
}
Ví dụ: Đọc hình ảnh từ hệ thống tệp
Hãy cùng xây dựng một công cụ đọc hình ảnh từ đĩa cứng và trả về cho mô hình để mô tả. Đầu tiên, hãy lấy Gemini API key và cài đặt Google GenAI SDK:
pip install google-genai
export GEMINI_API_KEY="your-api-key"
1. Định nghĩa công cụ
read_image = {
"type": "function",
"name": "read_image",
"description": "Đọc một tệp hình ảnh từ đĩa và trả về nội dung của nó.",
"parameters": {
"type": "object",
"properties": {
"path": {
"type": "string",
"description": "Đường dẫn đến tệp hình ảnh cần đọc"
}
},
"required": ["path"]
}
}
2. Triển khai thực thi công cụ
import base64
from pathlib import Path
def execute_read_image(path: str) -> list[dict]:
"""Đọc hình ảnh từ đĩa và trả về dưới dạng nội dung kết quả của hàm."""
image_path = Path(path)
if not image_path.exists():
return [{"type": "text", "text": f"Lỗi: Không tìm thấy hình ảnh tại {path}"}]
mime_types = {
".jpg": "image/jpeg",
".jpeg": "image/jpeg",
".png": "image/png",
".webp": "image/webp",
}
mime_type = mime_types.get(image_path.suffix.lower(), "image/png")
# Mã hóa hình ảnh sang base64
image_data = base64.b64encode(image_path.read_bytes()).decode()
return [{"type": "image", "data": image_data, "mime_type": mime_type}]
3. Tạo vòng lặp tác nhân (Agentic Loop)
from google import genai client = genai.Client() image_path = "duong/dan/den/anh/cua/ban.png" prompt = f"Sử dụng công cụ read_image để đọc '{image_path}' và mô tả những gì bạn thấy." # Bước 1: Gửi yêu cầu ban đầu kèm theo công cụ của chúng ta interaction = client.interactions.create( model="gemini-3-flash-preview", input=prompt, tools=[read_image], ) # Bước 2: Xử lý lệnh gọi hàm (function call) for output in interaction.outputs: if output.type == "function_call" and output.name == "read_image": image_result = execute_read_image(output.arguments.get("path")) # Bước 3: Gửi hình ảnh ngược lại cho mô hình interaction = client.interactions.create( model="gemini-3-flash-preview", input=[{ "type": "function_result", "call_id": output.id, "name": output.name, "result": image_result, # Chứa dữ liệu hình ảnh! }], tools=[read_image], previous_interaction_id=interaction.id, ) # Bước 4: Nhận mô tả từ mô hình for out in interaction.outputs: if out.type == "text": print(out.text)
Tóm tắt cách thức hoạt động
Luồng tương tác bao gồm bốn bước:
- Yêu cầu từ người dùng: Bạn gửi một câu lệnh yêu cầu mô hình sử dụng công cụ.
- Gọi hàm (Function call): Mô hình phản hồi bằng một function_call chỉ định công cụ nào cần dùng và các đối số đi kèm.
- Thực thi công cụ: Bạn thực thi công cụ và trả về kết quả (bao gồm cả hình ảnh).
- Phản hồi của mô hình: Mô hình xử lý hình ảnh và tạo ra mô tả bằng văn bản.
Kết luận
Gọi hàm đa phương thức mở ra các trường hợp sử dụng tác nhân đa phương thức mới. Bằng cách trả về hình ảnh trực tiếp trong function_result, bạn cung cấp cho Gemini 3 khả năng nhìn thấy những gì công cụ của bạn thấy.
Mô hình này không chỉ giới hạn ở việc đọc tệp. Bạn có thể xây dựng các công cụ chụp ảnh màn hình, lấy hình ảnh từ API, vẽ biểu đồ hoặc xử lý các tài liệu quét. Kết hợp với các phiên làm việc có trạng thái (stateful) của Interactions API, bạn có mọi thứ cần thiết để xây dựng các tác nhân thị giác tinh vi.
Các bước tiếp theo:
- Thử nghiệm với notebook Interactions API quickstart.
- Khám phá Computer Use để tự động hóa trình duyệt với phản hồi bằng hình ảnh.
- Xây dựng các công cụ trả về tệp PDF hoặc nhiều hình ảnh cho các quy trình làm việc với tài liệu phức tạp.
Nguồn bài viết từ Tác giả Phil Schmid


