
Danh mục:
Trong quá trình xử lý dữ liệu thô (raw-data) lấy từ các nguồn bên ngoài, thực hiện loại bỏ dữ liệu trùng lặp, thiết lập mối quan hệ giữa các tập dữ liệu và làm sạch dữ liệu (cleansing), tôi xin chia sẻ tóm tắt nội dung về việc cải thiện từng bước hiệu suất xử lý dữ liệu dung lượng lớn. Bài viết này là hướng dẫn tổng quát về chiến lược từng bước để cải thiện các điểm nghẽn hiệu suất. Mỗi bước là một phương pháp tiếp cận hiệu quả đã được áp dụng theo trình tự thực tế.
Bước 1: Upsert hàng loạt (Batch) dựa trên ORM cơ bản
- Sử dụng ORM để xử lý upsert nhiều bản ghi cùng một lúc.
- Ví dụ: SQLAlchemy + PostgreSQL ON CONFLICT.
- Vấn đề:
+ Khi xử lý lượng dữ liệu lớn, có thể vượt quá giới hạn số lượng tham số SQL (32767).
+ Tốc độ xử lý chậm do overhead của ORM.
Mẫu Code:
# imports ... async def upsert_many(self, records: List[DrugDocumentParagraphRecord]) -> int: if not records: return 0 total_upserted = 0 batch_size = 50 # Thử với kích thước nhỏ trước, sau đó tăng dần khi thấy ổn định. for i in range(0, len(records), batch_size): batch = records[i:i + batch_size] stmt = self._build_upsert_stmt(batch) result = await self._execute_statement(stmt) total_upserted += self._get_row_count(result) return total_upserted ... def _build_upsert_stmt( self, records: Union[NormalizedHeavyRecord, List[NormalizedHeavyRecord]] ) -> Executable: is_bulk = isinstance(records, list) model = NormalizedHeavyRecord # Trích xuất tất cả các khóa cột ngoại trừ khóa chính (`id`) # content_hash là khóa duy nhất cho dữ liệu, vì vậy bạn cần xây dựng và lưu nó cùng với dữ liệu mapper = class_mapper(model) column_keys = [col.key for col in mapper.columns if col.key not in ("id", "content_hash")] insert_stmt = pg_insert(model) ... # Loại bỏ _sa_instance_state (được thêm bởi SQLAlchemy ORM) ...
Bước 2: Áp dụng xử lý Batch quy mô nhỏ
- Chia toàn bộ dữ liệu thành kích thước nhất định (batch_size) và xử lý lặp lại.
- Ví dụ:
batch_size = 500 ~ 1000
- Ưu điểm:
+ Giảm gánh nặng cho transaction.
+ Tránh được giới hạn tham số (parameter limit).
- Hạn chế:
+ Hiệu quả cải thiện hiệu suất còn hạn chế.
Bước 3: Xử lý song song với async worker
- Áp dụng thực thi song song dựa trên asyncio.
- Sử dụng asyncio.Semaphore(n) để xử lý đồng thời n transaction.
- Ưu điểm: Phù hợp cho các tác vụ nhiều I/O.
- Lưu ý:
+ Cần tách biệt session.
+ Rollback đơn vị transaction chỉ khả thi cho từng cá nhân (từng worker).
Mẫu Code:
async def persist_doc_paragraphs(): records = all_data semaphore = asyncio.Semaphore(5) batch_size = 300 async def worker(batch): async with semaphore: async with factory() as session: # Cần tạo session riêng repository = NormalizedHeavyRecordRepository(session) return await repository.upsert_many(batch) tasks = [worker(records[i:i + batch_size]) for i in range(0, len(records), batch_size)] results = await asyncio.gather(*tasks) return sum(results)
Bước 4: COPY + Bảng tạm (Temporary Table) + ON CONFLICT UPDATE
- Sử dụng lệnh
COPYđể nhập vào bảng tạm, sau đó dùngINSERT INTO target SELECT...FROM tmp ON CONFLICT(...) DO UPDATE. - Thời điểm áp dụng: Khi số lượng bản ghi từ hàng nghìn đến hàng triệu trở lên.
- Vấn đề chính:
+ Cần loại bỏ các ký tự tab, xuống dòng trong các trường chuỗi (string).
+ Khớp kiểu dữ liệu (Ví dụ: Chú ý khi ép kiểu TEXT → INT).
- Ưu điểm:
+ Hiệu suất nhanh hơn gấp hàng chục lần.
+ Thực hiện upsert dữ liệu hiện có một cách an toàn.
+ Kết hợp COPY và upsert để đạt hiệu suất mạnh mẽ nhất.
Quy trình ví dụ:
- Tạo bảng tạm (
ON COMMIT DROP). -
COPY INTObảng tạm. -
INSERT INTObảng thực tế +ON CONFLICT.
Mẫu Code:
async def upsert_many_by_copy(self, records: List[NormalizedHeavyRecord], batch_size: int = 10000) -> int: ... # COPY ... FROM STDIN conn = await self.session.connection() raw_conn = await conn.get_raw_connection() pg_conn = raw_conn.driver_connection # ← Điểm cốt lõi # COPY vào bảng tạm async with pg_conn.transaction(): tmp_table_name = "tmp_sample_data" target_table_name = "sample_data" await self.create_tmp_table(columns, pg_conn, tmp_table_name) await self.copy_data_to_tmp_table(batch, columns, pg_conn, tmp_table_name) result = await self.insert_data_to_target_table(columns, pg_conn, target_table_name, tmp_table_name) # Ví dụ: 'INSERT 0 5231' → trích xuất số lượng hàng count = int(result.split()[-1]) return count async def insert_data_to_target_table(self, columns, pg_conn, target_table_name, tmp_table_name): # Định nghĩa các cột cần ép kiểu format: column_name: TYPE(e.g. INTEGER) type_casts = {} # INSERT FROM tmp → ON CONFLICT UPSERT vào bảng chính select_clause = await self.build_select_clause(columns, type_casts) update_clause = await self.build_update_clause(columns) insert_sql = f""" INSERT INTO {target_table_name} ({", ".join(columns)}) SELECT {select_clause} FROM {tmp_table_name} ON CONFLICT (content_hash) DO UPDATE SET {update_clause}; """ result = await pg_conn.execute(insert_sql) return result async def copy_data_to_tmp_table(self, batch, columns, pg_conn, tmp_table_name): # Chuyển đổi sang CSV # asyncpg yêu cầu nguồn phải là đối tượng dạng bytes (không phải str) buffer = await self.build_csv_buffer(batch, columns) # COPY INTO bảng tạm await pg_conn.copy_to_table( table_name=tmp_table_name, source=buffer, format="text", columns=columns ) async def create_tmp_table(self, columns, pg_conn, tmp_table_name): await pg_conn.execute(f""" CREATE TEMP TABLE {tmp_table_name} ( {', '.join(f"{col} TEXT" for col in columns)} ) ON COMMIT DROP; """) ...
Bước 5: Tiền xử lý là bắt buộc! Giai đoạn Sanitize (Làm sạch)
- Đối với
COPY, khả năng xảy ra lỗi cao do thiếu trường dữ liệu, không khớp kiểu, hoặc bản ghi bị vỡ do ký tự xuống dòng. - Các hạng mục xử lý Sanitize:
+ None →
N
+ Loại bỏ Tab/Xuống dòng/Carriage Return.
+ Xử lý
strip (cắt khoảng trắng đầu cuối).+ Làm rõ kiểu dữ liệu (str/int).
Mẫu Code:
def _sanitize(self, value): _value = value if _value is None: return r"N" if isinstance(_value, str): # Xử lý an toàn cho COPY: loại bỏ tab/xuống dòng _value = (re.sub(r'[rnt]+', ' ', _value) .replace("\", "\\") .strip()) return str(_value) async def build_csv_buffer(self, batch, columns): buffer = io.BytesIO() for idx, r in enumerate(batch): row = [self._sanitize(getattr(r, col, None)) for col in columns] if len(row) != len(columns): logger.warning(f"[COPY] ❗ Lỗi độ dài hàng tại index={idx} → nhận được {len(row)} trường") continue buffer.write(("t".join(row) + "n").encode("utf-8")) buffer.seek(0) return buffer
Bước 6: Áp dụng dần dần và mở rộng COPY song song
- Kết hợp các chiến lược trên để cấu hình như sau:
- Chia nhỏ thành các đơn vị batch quy mô nhỏ.
- Triển khai song song từng batch bằng
async. - Sử dụng
COPYtrong mỗi batch.
Phụ lục: Những điều cần cân nhắc khi kiểm thử
- Kích thước DB connection pool (chú ý vượt quá số lượng kết nối đồng thời).
- Thiết lập Retry và Timeout của Airflow/ETL Scheduler.
- Kiểm tra tính toàn vẹn của dữ liệu (Ví dụ:
row count, so sánhhash,diff log).
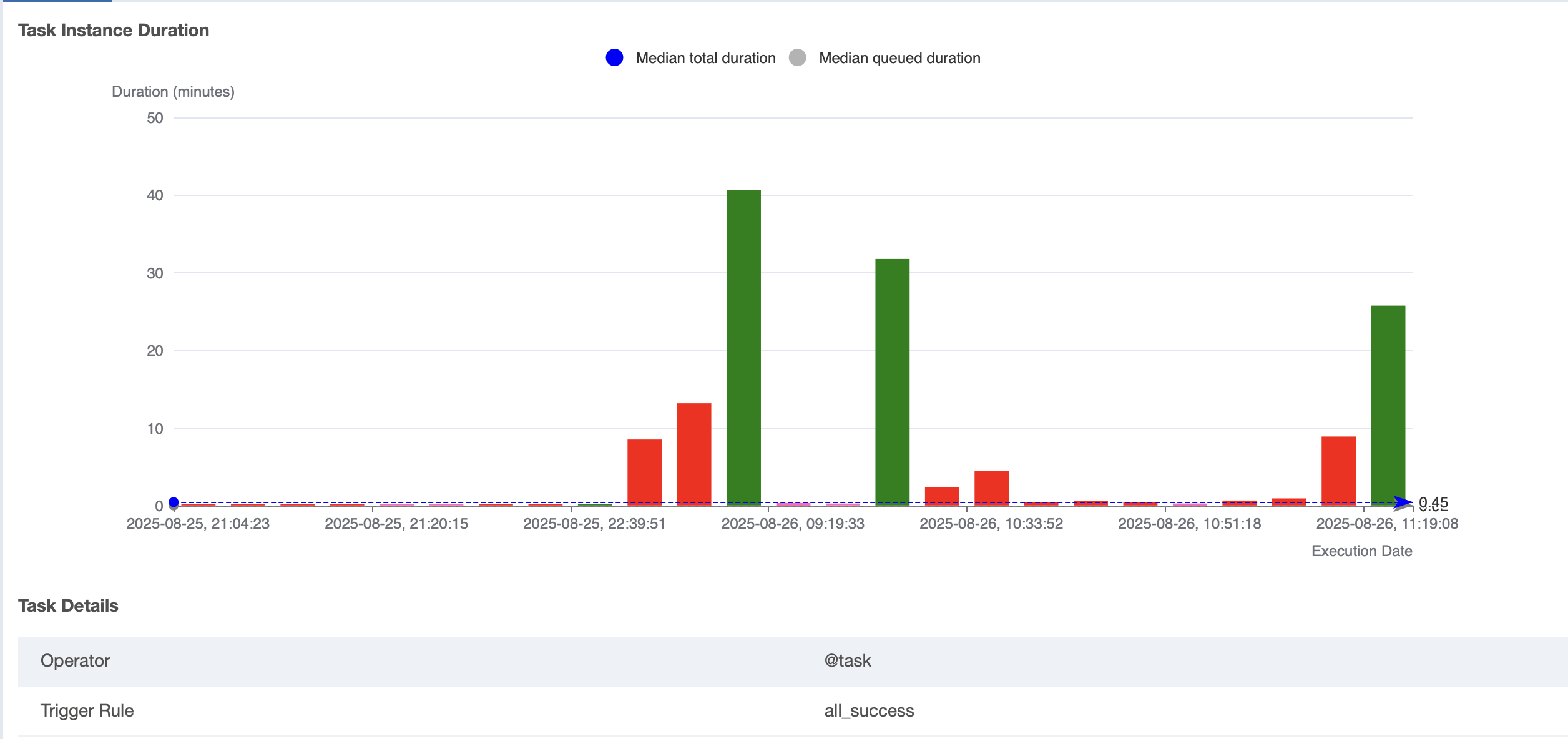
Cuối cùng, trong trường hợp của tôi, công việc từng mất 40 phút đã được rút ngắn xuống còn 25 phút. Hãy tham khảo biểu đồ bên dưới. :)
Nguồn bài viết Dịch từ ryukato.github.io


